
kernel note
kernel笔记
首先是要配置环境,推荐[wiki](Qemu 模拟环境 - CTF Wiki (ctf-wiki.org))和这篇文章
其中调试部分我还搁置着准备等学有所成再来实战
可以将内核看作一个巨大的elf,它又有数据段
基础知识
Kernel
kernel 也是一个程序,用来管理软件发出的数据 I/O 要求,将这些要求转义为指令,交给 CPU 和计算机中的其他组件处理,kernel 是现代操作系统最基本的部分。

kernel 最主要的功能有两点:
- 控制并与硬件进行交互
- 提供 application 能运行的环境
包括 I/O,权限控制,系统调用,进程管理,内存管理等多项功能都可以归结到上边两点中。
需要注意的是,kernel 的 crash 通常会引起重启。
Ring Model
intel CPU 将 CPU 的特权级别分为 4 个级别:Ring 0, Ring 1, Ring 2, Ring 3。
Ring0 只给 OS 使用,Ring 3 所有程序都可以使用,内层 Ring 可以随便使用外层 Ring 的资源。
使用 Ring Model 是为了提升系统安全性,例如某个间谍软件作为一个在 Ring 3 运行的用户程序,在不通知用户的时候打开摄像头会被阻止,因为访问硬件需要使用 being 驱动程序保留的 Ring 1 的方法。
大多数的现代操作系统只使用了 Ring 0 和 Ring 3。
Loadable Kernel Modules(LKMs)
可加载核心模块 (或直接称为内核模块) 就像运行在内核空间的可执行程序,包括:
- 驱动程序(Device drivers)
- 设备驱动
- 文件系统驱动
- …
- 内核扩展模块 (modules)
LKMs 的文件格式和用户态的可执行程序相同,Linux 下为 ELF,Windows 下为 exe/dll,mac 下为 MACH-O,因此我们可以用 IDA 等工具来分析内核模块。
模块可以被单独编译,但不能单独运行。它在运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户控件的进程不同。
模块通常用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
Linux 内核之所以提供模块机制,是因为它本身是一个单内核 (monolithic kernel)。单内核的优点是效率高,因为所有的内容都集合在一起,但缺点是可扩展性和可维护性相对较差,模块机制就是为了弥补这一缺陷。
相关指令
- insmod: 讲指定模块加载到内核中
- rmmod: 从内核中卸载指定模块
- lsmod: 列出已经加载的模块
- modprobe: 添加或删除模块,modprobe 在加载模块时会查找依赖关系
大多数 CTF 中的 kernel vulnerability 也出现在 LKM 中。
syscall
系统调用,指的是用户空间的程序向操作系统内核请求需要更高权限的服务,比如 IO 操作或者进程间通信。系统调用提供用户程序与操作系统间的接口,部分库函数(如 scanf,puts 等 IO 相关的函数实际上是对系统调用的封装(read 和 write))。
在 /usr/include/x86_64-linux-gnu/asm/unistd_64.h 和 /usr/include/x86_64-linux-gnu/asm/unistd_32.h 分别可以查看 64 位和 32 位的系统调用号。
同时推荐一个很好用的网站 Linux Syscall Reference,可以查阅 32 位系统调用对应的寄存器含义以及源码。64 位系统调用可以查看 Linux Syscall64 Reference
ioctl
直接查看 man 手册
1 | NAME |
可以看出 ioctl 也是一个系统调用,用于与设备通信。
int ioctl(int fd, unsigned long request, ...) 的第一个参数为打开设备 (open) 返回的 文件描述符,第二个参数为用户程序对设备的控制命令,再后边的参数则是一些补充参数,与设备有关。
使用 ioctl 进行通信的原因:
操作系统提供了内核访问标准外部设备的系统调用,因为大多数硬件设备只能够在内核空间内直接寻址, 但是当访问非标准硬件设备这些系统调用显得不合适, 有时候用户模式可能需要直接访问设备。
比如,一个系统管理员可能要修改网卡的配置。现代操作系统提供了各种各样设备的支持,有一些设备可能没有被内核设计者考虑到,如此一来提供一个这样的系统调用来使用设备就变得不可能了。
为了解决这个问题,内核被设计成可扩展的,可以加入一个称为设备驱动的模块,驱动的代码允许在内核空间运行而且可以对设备直接寻址。一个 Ioctl 接口是一个独立的系统调用,通过它用户空间可以跟设备驱动沟通。对设备驱动的请求是一个以设备和请求号码为参数的 Ioctl 调用,如此内核就允许用户空间访问设备驱动进而访问设备而不需要了解具体的设备细节,同时也不需要一大堆针对不同设备的系统调用。
状态切换
user space to kernel space
当发生 系统调用,产生异常,外设产生中断等事件时,会发生用户态到内核态的切换,具体的过程为:
通过
swapgs切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用。将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入 rsp/esp。
通过 push 保存各寄存器值,具体的 代码 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27ENTRY(entry_SYSCALL_64)
/* SWAPGS_UNSAFE_STACK是一个宏,x86直接定义为swapgs指令 */
SWAPGS_UNSAFE_STACK
/* 保存栈值,并设置内核栈 */
movq %rsp, PER_CPU_VAR(rsp_scratch)
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* 通过push保存寄存器值,形成一个pt_regs结构 */
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx tuichu /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */通过汇编指令判断是否为
x32_abi。通过系统调用号,跳到全局变量
sys_call_table相应位置继续执行系统调用。
kernel space to user space
退出时,流程如下:
- 通过
swapgs恢复 GS 值 - 通过
sysretq或者iretq恢复到用户控件继续执行。如果使用iretq还需要给出用户空间的一些信息(CS, eflags/rflags, esp/rsp 等)
struct cred
之前提到 kernel 记录了进程的权限,更具体的,是用 cred 结构体记录的,每个进程中都有一个 cred 结构,这个结构保存了该进程的权限等信息(uid,gid 等),如果能修改某个进程的 cred,那么也就修改了这个进程的权限。
源码 如下:
1 | struct cred { |
内核态函数
相比用户态库函数,内核态的函数有了一些变化
printf() -> **printk()**,但需要注意的是 printk() 不一定会把内容显示到终端上,但一定在内核缓冲区里,可以通过
dmesg查看效果memcpy() ->
copy_from_user()/copy_to_user()
- copy_from_user() 实现了将用户空间的数据传送到内核空间
- copy_to_user() 实现了将内核空间的数据传送到用户空间
malloc() -> **kmalloc()**,内核态的内存分配函数,和 malloc() 相似,但使用的是
slab/slub 分配器free() -> **kfree()**,同 kmalloc()
另外要注意的是,kernel 管理进程,因此 kernel 也记录了进程的权限。kernel 中有两个可以方便的改变权限的函数:
- int commit_creds(struct cred *new)
- struct cred* prepare_kernel_cred(struct task_struct* daemon)
从函数名也可以看出,执行 commit_creds(prepare_kernel_cred(0)) 即可获得 root 权限,0 表示 以 0 号进程作为参考准备新的 credentials。
更多关于
prepare_kernel_cred的信息可以参考 源码
执行 commit_creds(prepare_kernel_cred(0)) 也是最常用的提权手段,两个函数的地址都可以在 /proc/kallsyms 中查看(较老的内核版本中是 /proc/ksyms)。
1 | post sudo grep commit_creds /proc/kallsyms |
一般情况下,/proc/kallsyms 的内容需要 root 权限才能查看
Mitigation
canary, dep, PIE, RELRO 等保护与用户态原理和作用相同
- smep: Supervisor Mode Execution Protection,当处理器处于
ring0模式,执行用户空间的代码会触发页错误。(在 arm 中该保护称为PXN) - smap: Superivisor Mode Access Protection,类似于 smep,通常是在访问数据时。
- mmap_min_addr:是一个内核参数,用于限制用户空间可以使用的最低内存地址。
CTF kernel pwn 相关
一般会给以下三个文件
boot.sh: 一个用于启动 kernel 的 shell 的脚本,多用 qemu,保护措施与 qemu 不同的启动参数有关
bzImage: kernel binary
rootfs.cpio: 文件系统映像
比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24CISCN2017_babydriver [master●] ls
babydriver.tar
CISCN2017_babydriver [master●] x babydriver.tar
boot.sh
bzImage
rootfs.cpio
CISCN2017_babydriver [master●] ls
babydriver.tar boot.sh bzImage rootfs.cpio
CISCN2017_babydriver [master●] file bzImage
bzImage: Linux kernel x86 boot executable bzImage, version 4.4.72 (atum@ubuntu) #1 SMP Thu Jun 15 19:52:50 PDT 2017, RO-rootFS, swap_dev 0x6, Normal VGA
CISCN2017_babydriver [master●] file rootfs.cpio
rootfs.cpio: gzip compressed data, last modified: Tue Jul 4 08:39:15 2017, max compression, from Unix, original size 2844672
CISCN2017_babydriver [master●] file boot.sh
boot.sh: Bourne-Again shell script, ASCII text executable
CISCN2017_babydriver [master●] bat boot.sh
───────┬─────────────────────────────────────────────────────────────────────────────────
│ File: boot.sh
───────┼─────────────────────────────────────────────────────────────────────────────────
1 │ #!/bin/bash
2 │
3 │ qemu-system-x86_64 -initrd rootfs.cpio -kernel bzImage -append 'console=ttyS0 ro
│ ot=/dev/ram oops=panic panic=1' -enable-kvm -monitor /dev/null -m 64M --nographi
│ c -smp cores=1,threads=1 -cpu kvm64,+smep
───────┴─────────────────────────────────────────────────────────────────────────────────解释一下 qemu 启动的参数:
- -initrd rootfs.cpio,使用 rootfs.cpio 作为内核启动的文件系统
- -kernel bzImage,使用 bzImage 作为 kernel 映像
- -cpu kvm64,+smep,设置 CPU 的安全选项,这里开启了 smep
- -m 64M,设置虚拟 RAM 为 64M,默认为 128M 其他的选项可以通过 –help 查看。
本地写好 exploit 后,可以通过 base64 编码等方式把编译好的二进制文件保存到远程目录下,进而拿到 flag。同时可以使用 musl, uclibc 等方法减小 exploit 的体积方便传输。
在 Linux 内核漏洞利用中,攻击者可能会有以下几个目的
- 提权,即获取到 root 权限。
- 泄露敏感信息。
- DoS,即使得内核崩溃。
一般而言,攻击者的主要目的是提权。
Privilege Escalation
Introduction
内核提权指的是普通用户可以获取到 root 用户的权限,访问原先受限的资源。这里从两种角度来考虑如何提权
- 改变自身:通过改变自身进程的权限,使其具有 root 权限。
- 改变别人:通过影响高权限进程的执行,使其完成我们想要的功能。
Change Self
内核会通过进程的 task_struct 结构体中的 cred 指针来索引 cred 结构体,然后根据 cred 的内容来判断一个进程拥有的权限,如果 cred 结构体成员中的 uid-fsgid 都为 0,那一般就会认为进程具有 root 权限。
1 | struct cred { |
因此,思路就比较直观了,我们可以通过以下方式来提权
- 直接修改 cred 结构体的内容
- 修改 task_struct 结构体中的 cred 指针指向一个满足要求的 cred
无论是哪一种方法,一般都分为两步:定位,修改。这就好比把大象放到冰箱里一样。
直接改 cred
定位具体位置
我们可以首先获取到 cred 的具体地址,然后修改 cred。
定位
定位 cred 的具体地址有很多种方法,这里根据是否直接定位分为以下两种
直接定位
cred 结构体的最前面记录了各种 id 信息,对于一个普通的进程而言,uid-fsgid 都是执行进程的用户的身份。因此我们可以通过扫描内存来定位 cred。
1 | struct cred { |
在实际定位的过程中,我们可能会发现很多满足要求的 cred,这主要是因为 cred 结构体可能会被拷贝、释放。一个很直观的想法是在定位的过程中,利用 usage 不为 0 来筛除掉一些 cred,但仍然会发现一些 usage 为 0 的 cred。这是因为 cred 从 usage 为 0, 到释放有一定的时间。此外,cred 是使用 rcu 延迟释放的。
usage字段是cred结构体中的一个计数器,用于记录对该cred结构体的引用数。每当有一个进程引用该cred结构体时,usage计数就会增加;当引用结束时,计数就会减少。这个计数机制被用于管理cred结构体的生命周期和内存释放。
具体来说,usage的作用有以下几个方面:
- 引用计数:usage字段用于跟踪cred结构体的引用次数。通过增加和减少usage计数,内核可以确定何时可以安全地释放cred结构体的内存。
- 延迟释放:cred结构体的释放是通过RCU(Read-Copy-Update)机制来延迟执行的。当usage计数减少到0时,并不立即释放cred结构体的内存,而是延迟到合适的时机,以确保没有正在使用该cred结构体的代码存在。
- 进程共享:由于cred结构体可以被多个进程引用,通过共享同一个cred结构体,可以节省内存和提高性能。usage计数的增加和减少反映了cred结构体的引用情况,确保在没有进程引用时才释放相关的资源。
在定位cred结构体的过程中,通过检查usage字段可以了解当前有多少进程正在引用该cred结构体。如果发现usage为0,表示当前没有进程引用该cred结构体,可能可以安全地释放它。但需要注意的是,由于RCU的延迟释放机制,即使usage为0,cred结构体的内存也可能不会立即释放,而是会在合适的时机进行释放。
间接定位
task_struct
进程的 task_struct 结构体中会存放指向 cred 的指针,因此我们可以
- 定位当前进程
task_struct结构体的地址 - 根据 cred 指针相对于 task_struct 结构体的偏移计算得出
cred指针存储的地址 - 获取
cred具体的地址
comm
comm 用来标记可执行文件的名字,位于进程的 task_struct 结构体中。我们可以发现 comm 其实在 cred 的正下方,所以我们也可以先定位 comm ,然后定位 cred 的地址。
1 | /* Process credentials: */ |
然而,在进程名字并不特殊的情况下,内核中可能会有多个同样的字符串,这会影响搜索的正确性与效率。因此,我们可以使用 prctl 设置进程的 comm 为一个特殊的字符串,然后再开始定位 comm。
在Linux系统中,prctl(Process Control)是一个系统调用,用于控制和修改进程的各种属性和行为。通过prctl系统调用,可以对进程进行各种操作,如设置进程的名称、获取和修改进程的资源限制、修改进程的信号处理方式等。
具体来说,prctl系统调用的功能包括但不限于以下几个方面:
- 进程名称(comm)的设置:可以使用prctl系统调用来设置进程的名称。进程名称是在进程表中标识进程的一个字符串。通过设置特殊的进程名称,可以在定位和识别进程时提供更多的信息。
- 进程资源限制的获取和修改:可以使用prctl系统调用来获取和修改进程的资源限制,如CPU时间限制、内存限制、文件描述符限制等。这可以帮助控制进程的资源使用情况,以及保护系统免受恶意进程的影响。
- 进程信号处理方式的修改:可以使用prctl系统调用来修改进程接收和处理信号的方式。可以设置进程忽略某些信号、捕获和处理某些信号,或者恢复默认的信号处理方式。
- 进程状态的获取和修改:可以使用prctl系统调用来获取和修改进程的状态信息,如进程的运行状态、终止状态等。这可以用于监控和管理进程的状态。
- 其他进程控制操作:prctl系统调用还提供其他一些进程控制操作,如设置线程名字、获取和修改进程的调度策略和优先级、获取和修改进程的安全上下文等。
通过使用prctl系统调用,可以对进程进行灵活的控制和管理,以满足特定的需求和场景。在定位进程时,可以使用prctl设置进程的名称(comm)为特殊的字符串,以便更方便地进行搜索和识别。
修改
在这种方法下,我们可以直接将 cred 中的 uid-fsgid 都修改为 0。当然修改的方式有很多种,比如说
- 在我们具有任意地址读写后,可以直接修改 cred。
- 在我们可以 ROP 执行代码后,可以利用 ROP gadget 修改 cred。
间接定位
虽然我们确实想要修改 cred 的内容,但是不一定非得知道 cred 的具体位置,我们只需要能够修改 cred 即可。
(已过时)UAF 使用同样堆块
如果我们在进程初始化时能控制 cred 结构体的位置,并且我们可以在初始化后修改该部分的内容,那么我们就可以很容易地达到提权的目的。这里给出一个典型的例子
- 申请一块与 cred 结构体大小一样的堆块
- 释放该堆块
- fork 出新进程,恰好使用刚刚释放的堆块
- 此时,修改 cred 结构体特定内存,从而提权
但是此种方法在较新版本内核中已不再可行,我们已无法直接分配到 cred_jar 中的 object,这是因为 cred_jar 在创建时设置了 SLAB_ACCOUNT 标记,在 CONFIG_MEMCG_KMEM=y 时(默认开启)cred_jar 不会再与相同大小的 kmalloc-192 进行合并
1 | void __init cred_init(void) |
内核的文件系统
dev文件
在Linux系统中,/dev目录是一个特殊的目录,用于表示设备文件。设备文件是用于与系统中的硬件设备或其他特殊设备进行交互的接口。/dev目录中的文件对应着系统中的各种设备,包括磁盘驱动器、串口、打印机等。
下面是一些常见的/dev目录中的设备文件及其含义:
/dev/null:一个特殊的设备文件,用于丢弃所有写入它的数据。读取它将立即返回文件结束。/dev/zero:一个特殊的设备文件,用于提供无限的零字节数据。读取它将返回连续的零字节。/dev/random和/dev/urandom:这些设备文件用于生成随机数据。/dev/random提供高质量的随机数据,但当熵池耗尽时会阻塞读取操作。/dev/urandom则不会阻塞,但在熵池耗尽时可能提供较低质量的随机数据。/dev/tty:代表当前终端设备的设备文件。它通常用于与终端进行交互,例如读取键盘输入或向终端输出数据。/dev/sda、/dev/sdb等:这些设备文件表示系统中的物理磁盘驱动器。每个磁盘驱动器都被分配一个相应的设备文件,用于进行磁盘操作,如读取和写入数据。/dev/input/eventX:这些设备文件表示输入设备,如键盘、鼠标和触摸屏。每个输入设备都被分配一个对应的设备文件,用于读取设备的输入事件。/dev/videoX:这些设备文件代表视频设备,如摄像头。每个视频设备都被分配一个对应的设备文件,用于捕获视频数据。
bin文件
在计算机领域中,”bin”一词通常是指二进制文件(Binary file)。二进制文件是一种以二进制形式存储的文件,其中包含计算机可执行代码或非文本数据。
二进制文件与文本文件不同,它们不是使用可读的字符编码(如ASCII或UTF-8)表示的文本数据,而是以机器可执行的二进制形式存储的数据。二进制文件可以包含编译后的程序代码、可执行文件、库文件、图像、音频、视频等各种非文本数据。
二进制文件通常由编译器、链接器或其他工具生成,用于在计算机上执行特定的操作。例如,可执行文件(executable file)是一种特殊的二进制文件,包含了计算机可直接执行的指令和数据,用于运行程序。库文件(library file)是包含可重用代码和函数的二进制文件,用于在程序开发中进行链接和共享。
二进制文件的内容对于人类来说通常是不可读的,因为它们不是使用文本编码表示的。要查看二进制文件的内容,通常需要使用特定的工具或程序进行解析和处理。
总结起来,”bin”文件是指二进制文件,其中包含了以二进制形式存储的计算机可执行代码或非文本数据。它们在计算机系统中起着重要的作用,用于存储和执行各种类型的程序和数据。
etc文件
在类Unix操作系统中,/etc目录是一个非常重要的目录,它用于存放系统的配置文件。这个目录包含了系统大部分的配置文件和子目录。我们可以将其视为系统的“设置中心”。下面是一些/etc目录下常见的文件和子目录的中文详解:
- **
/etc/passwd**:这是一个用户账户信息文件,记录了系统上每个用户的基本信息,例如用户ID、组ID、家目录、登录shell等。虽然这个文件包含密码信息的位置,但现代系统中密码通常是加密后存储在/etc/shadow中。 - **
/etc/shadow**:存储加密后的用户密码以及与密码相关的管理信息,如密码更改日期、过期时间等。出于安全考虑,这个文件的读权限非常严格,通常只有超级用户(root)可以访问。 - **
/etc/group**:类似于/etc/passwd,但这个文件记录的是组的信息,包括组名、组密码(很少使用)、组ID以及属于该组的用户列表。 - **
/etc/fstab**:文件系统表,这个文件包含了系统启动时需要挂载的分区和存储设备的信息,包括设备名、挂载点、文件系统类型、挂载选项等。 - **
/etc/hosts**:这是一个本地DNS解析文件,用于将主机名映射到IP地址。在进行DNS查询之前,系统会首先检查这个文件。 - **
/etc/resolv.conf**:DNS客户端的配置文件,指定了系统解析域名时应该查询的DNS服务器的IP地址。 - **
/etc/sysctl.conf**:用于配置内核参数的文件。系统管理员可以通过编辑这个文件来调整和优化系统的运行参数。 - **
/etc/crontab**:系统定时任务配置文件,允许系统管理员安排在特定时间自动执行的任务。 - **
/etc/services**:这个文件列出了网络服务和对应的端口号,例如HTTP通常对应端口80。这有助于软件和服务找到它们应该使用的标准端口。 - **
/etc/network/interfaces**(在一些系统中):网络接口配置文件,用于设置网络接口的IP地址、子网掩码、网关等网络参数。
这只是/etc目录下一小部分文件和目录的简介。/etc目录下的文件和子目录数量众多,且随着不同的发行版和系统配置的不同而有所变化。管理员和高级用户通常需要根据具体需求编辑这些文件来配置系统。
home文件
在类Unix操作系统中,/home目录扮演着非常重要的角色,它是用户的个人目录的默认存放位置。每个在系统上有账户的普通用户都会在/home目录下拥有一个与其用户名同名的目录,用来存储个人文件、配置文件、用户级的程序设置等。以下是对/home目录的详细解释:
/home目录的作用
- 用户数据存储:用户可以在自己的
/home子目录中存储个人文件、文档、图片、音乐等数据。 - 用户配置文件:很多程序会在用户的
/home子目录中创建隐藏文件或目录(文件或目录名以.开头)来存储程序的用户级配置。例如,浏览器可能会在用户的/home子目录下创建一个隐藏的配置目录来存储书签和历史记录。 - 用户级软件安装:用户可以在自己的
/home目录下安装软件或脚本,这些软件或脚本只对当前用户有效,不影响系统中的其他用户。
/home目录的特点
- 隔离性:每个用户的
/home子目录是独立的,这意味着一个用户默认情况下无法访问另一个用户的/home子目录。这提供了一定程度的数据隔离和隐私保护。 - 备份与迁移:由于用户的个人数据和配置都存储在
/home目录下,这使得备份和迁移用户数据变得相对简单。系统管理员可以通过备份整个/home目录来备份所有用户的个人数据。 - 灵活性:如果系统需要重新安装或升级,通常不需要对
/home目录进行更改,这意味着用户的个人设置和数据可以在系统升级或重装后保持不变。
注意事项
- 存储空间管理:在有限的磁盘空间情况下,
/home目录可能会成为存储空间不足的瓶颈。因此,管理好/home目录下的存储空间使用情况是很重要的。 - 安全性:虽然
/home目录提供了用户数据的隔离,但是如果系统的安全设置不当,恶意用户或程序仍然有可能访问或修改其他用户的数据。因此,保持系统的安全更新和合理配置权限是非常重要的。
总的来说,/home目录是类Unix操作系统中非常关键的一个组成部分,它为用户提供了一个存储个人数据和配置的空间,同时也带来了一系列的管理和安全上的考虑。
lib文件
在类Unix操作系统中,/lib目录是一个关键的系统目录,用于存放操作系统运行所需的基本共享库文件和内核模块。这些库文件对于系统的正常运行至关重要,因为它们提供了许多基本的功能,供不同的程序和服务调用。以下是对/lib目录的详细解释:
/lib目录的作用
- 共享库:
/lib目录包含了系统最基本的共享库文件,这些文件类似于Windows操作系统中的DLL文件。它们提供了许多常用的功能,如文件操作、数学计算、字符串处理等,可以被系统中的多个程序共同使用。 - 内核模块:
/lib目录还存放了内核模块(在/lib/modules目录下),这些模块可以在系统运行时动态加载或卸载,用于支持硬件设备、文件系统类型等。
/lib目录的特点
- 核心依赖:
/lib目录中的文件是系统启动和运行的核心依赖。例如,即使是最基本的命令行工具,如ls或bash,也需要调用/lib目录中的库文件来执行。 - 动态链接:存放在
/lib目录中的共享库文件通常是动态链接的,意味着程序在运行时才会加载这些库文件。这种方式可以减少程序的磁盘和内存占用,因为多个程序可以共享同一份库文件,而不是每个程序都包含自己的库副本。
/lib目录下的重要子目录
- **
/lib32和/lib64**:在64位系统中,/lib目录可能会包含/lib32和/lib64子目录,分别用于存放32位和64位的库文件。这样做是为了保持对32位应用程序的兼容性。 - **
/lib/modules**:存放内核模块的目录,这些模块可以根据需要动态加载到内核中。
注意事项
- 系统稳定性:由于
/lib目录包含了系统的核心库文件,任何对这些文件的不当修改都可能导致系统不稳定或无法启动。 - 安全性:库文件是攻击者常见的攻击目标之一,因为它们通常具有高权限且被广泛使用。因此,保持系统和库文件的更新是非常重要的。
总的来说,/lib目录是类Unix操作系统中非常关键的一个组成部分,它为系统提供了核心的共享库和内核模块,使得系统能够高效地运行各种程序和服务。
proc文件
在类Unix操作系统中,/proc目录是一个特殊的目录,它并不存储在磁盘上,而是一个虚拟的文件系统,通常被称为proc文件系统。/proc提供了一个窗口,通过它可以查看运行中的内核和进程信息,以及修改某些内核参数。这个目录包含了大量的信息,既包括关于系统硬件的详细信息,也包括关于当前运行的进程的信息。以下是对/proc目录的详细解释:
/proc目录的作用
- 内核参数访问:
/proc目录允许用户和应用程序访问和修改内核参数。例如,/proc/sys目录下的文件可以用来动态调整内核的行为。 - 进程信息:对于系统上的每个进程,
/proc都有一个以进程ID命名的子目录,例如/proc/1234。这些目录包含了关于各个进程的详细信息,如内存映射、打开的文件描述符、进程状态等。 - 系统信息:
/proc目录提供了关于系统硬件和配置的信息,例如CPU信息(/proc/cpuinfo)、内存信息(/proc/meminfo)、分区表(/proc/partitions)等。
/proc目录的特点
- 虚拟的:
/proc是一个虚拟文件系统,它存在于内存中,不占用磁盘空间。这意味着其中的文件和目录是由内核动态生成的,以提供关于系统状态的实时信息。 - 可读写:虽然大多数
/proc下的文件是只读的,但有些文件是可写的,允许通过直接写入这些文件来修改内核参数。 - 实时性:
/proc目录下的信息是实时更新的,反映了当前系统的状态。
/proc目录下的一些重要文件和目录
/proc/cpuinfo:显示CPU的信息,如型号、核心数、速度等。/proc/meminfo:显示内存的详细使用信息,包括总内存、可用内存、缓存等。/proc/partitions:显示系统中所有分区的列表。/proc/sys:包含可以动态调整的内核参数。通过修改这里的文件,可以改变系统的行为。/proc/[pid]:每个正在运行的进程都有一个对应的目录,目录名为进程的PID。这些目录包含了关于进程的详细信息。
注意事项
- 安全性:由于
/proc目录提供了大量的系统信息和部分内核参数修改能力,恶意程序可能会尝试读取这些信息或修改参数以提升权限或进行攻击。因此,系统管理员需要留意对/proc目录的访问控制。 - 性能影响:频繁地访问或修改某些
/proc文件可能会对系统性能产生影响,特别是在高负载情况下。
总的来说,/proc目录是一个功能强大的工具,为系统管理员和开发者提供了一种方便的方式来监控和调整系统运行时的行为。
sbin文件
在类Unix操作系统中,/sbin目录是一个存放系统管理和维护程序的特殊目录。这个目录包含的程序通常是供系统管理员使用的,而不是普通用户。这些程序包括用于启动、修复、恢复和维护系统的各种工具。与/bin目录下的命令相比,/sbin目录下的命令更多地关注系统级别的操作和维护任务。以下是对/sbin目录的详细解释:
/sbin目录的作用
- 系统启动和恢复:
/sbin目录包含了启动系统所需的重要命令,如init、systemd或upstart。这些是系统初始化和管理服务的核心工具。 - 设备管理:这个目录下的命令包括用于管理硬件设备的程序,比如
fdisk、mkfs、fsck等,它们分别用于分区、格式化和检查文件系统。 - 网络配置:
/sbin还包含了配置网络的工具,例如ifconfig(尽管在一些现代的Linux发行版中,ifconfig已经被ip命令替代,并且可能位于/bin或/usr/bin目录)。 - 系统安全:包括用于设置和管理系统安全方面的命令,如
iptables用于配置防火墙规则。
/sbin目录的特点
- 专业性:与
/bin目录下的命令相比,/sbin目录下的命令更加专业,主要面向系统管理和维护。 - 访问限制:出于安全考虑,这些命令通常只有root用户或具有相应权限的用户才能执行。这是为了防止普通用户执行可能会影响系统稳定性和安全性的操作。
注意事项
- 谨慎使用:由于
/sbin目录下的命令具有很高的权限和强大的功能,不当的使用可能会导致系统不稳定甚至数据丢失。因此,只有在清楚命令作用的情况下才使用这些命令。 - 路径问题:在一些系统中,特别是在非root用户下,
/sbin目录可能不在默认的环境变量PATH中。如果需要执行/sbin目录下的命令,可能需要指定完整的路径或临时修改PATH变量。
总的来说,/sbin目录是类Unix操作系统中非常重要的一个目录,它包含了许多系统级别的管理和维护工具。了解和合理使用这些工具对于系统管理员来说非常重要。
sys文件
在类Unix操作系统中,/sys目录是一个虚拟文件系统,称为sysfs。sysfs提供了一种机制,使得内核空间能够将信息导出到用户空间,从而允许用户空间的程序和用户查询和控制内核中的设备和驱动程序的状态。与/proc文件系统相似,/sys也不占用磁盘空间,它在系统启动时由内核动态生成。以下是对/sys目录的详细解释:
/sys目录的作用
- 设备和驱动程序信息:
/sys提供了一种查看和交互式修改与系统硬件设备相关的信息的方法。每个硬件设备在/sys中都有一个对应的目录,通过这个目录,可以访问设备的属性、状态以及相关的驱动程序信息。 - 内核对象(kobjects)表示:sysfs使用内核对象(kobjects)来表示内核中的各种结构,如设备、驱动程序和内核模块。这为用户提供了一种直观的方式来浏览和修改这些对象的属性。
- 系统配置:除了提供设备信息,
/sys还允许某些参数的动态修改,这可以影响系统的运行方式和设备的配置。
/sys目录的特点
- 虚拟的:与
/proc一样,/sys是一个虚拟文件系统,它反映了内核的当前状态,但不占用实际的磁盘空间。 - 结构化:
/sys的结构比/proc更加直观和有组织,它按照设备类型和功能进行组织,使得查找特定设备或信息更加容易。 - 可读写:
/sys中的许多文件不仅可读,也可写。这允许用户或应用程序通过写入这些文件来改变设备的状态或配置。
/sys目录下的一些重要子目录
- **
/sys/block**:包含系统中所有块设备的信息,如硬盘和光驱。 - **
/sys/class**:按设备类型组织的设备信息,如/sys/class/net包含网络接口的信息。 - **
/sys/devices**:包含系统中所有设备的层次结构,这是按照物理或逻辑结构组织的。 - **
/sys/module**:包含当前加载的内核模块信息。
注意事项
- 谨慎修改:虽然
/sys提供了修改设备配置和参数的能力,但不恰当的修改可能会导致系统不稳定或硬件设备工作异常。因此,在修改/sys中的文件之前,应确保了解这些修改的含义和后果。 - 权限:修改
/sys中的文件通常需要管理员权限,因为这些更改可能会影响系统的整体运行。
总的来说,/sys目录是Linux内核提供的一种强大的机制,用于展示系统硬件信息和配置,它为用户和程序提供了直接与内核交互的能力。
tmp文件
在类Unix操作系统中,/tmp目录是一个用于存放临时文件的特殊目录。这个目录供系统和用户存放在短期内需要的文件,但这些文件随后可能会被删除或丢弃。/tmp目录对所有用户都是可写的,因此它是多用户环境下共享临时数据的一个常用位置。以下是对/tmp目录的详细解释:
/tmp目录的作用
- 临时数据存储:
/tmp提供了一个存储临时数据的地方,这些数据包括但不限于临时文件、处理中的数据文件、缓存文件等。 - 程序执行中间产物:很多程序在执行过程中会产生临时文件,这些文件用于存储中间结果或日志信息,执行完毕后通常会被删除。
- 用户和应用程序的临时文件:除了系统进程外,用户启动的应用程序也可能会在
/tmp中创建临时文件,用于各种临时需求。
/tmp目录的特点
- 易失性:
/tmp目录中的数据是易失的,这意味着在系统重启过程中,存储在其中的文件可能会被删除。一些系统在启动时会自动清理/tmp目录,而其他系统可能会运行定期的清理任务。 - 安全性:由于
/tmp是对所有用户可写的,因此存在一定的安全风险。恶意用户或程序可能会尝试利用/tmp目录中的文件执行攻击,或通过创建大量文件耗尽系统资源。 - 权限管理:系统通常会对
/tmp目录设置特定的权限和粘滞位(sticky bit),以防止用户删除或修改不属于他们的文件。
注意事项
- 定期清理:由于
/tmp用于存放临时文件,建议定期清理以释放磁盘空间,尤其是在磁盘空间较小的系统上。 - 安全措施:在使用
/tmp时,应该注意安全性,避免在其中存储敏感信息。同时,开发者在创建临时文件时应使用安全的方法,如使用mktemp命令或相应的库函数来创建唯一的临时文件名,以减少安全风险。 - 替代方案:对于需要长期存储的临时文件,应考虑使用其他目录,如用户的主目录下的临时文件夹,或者系统提供的其他临时存储位置,例如
/var/tmp。与/tmp不同,/var/tmp在系统重启后通常不会被清空。
总的来说,/tmp目录是一个用于存放临时文件的便利位置,但使用时需要注意数据的易失性和安全性问题。合理管理/tmp目录对于维护系统的稳定性和安全性非常重要。
进程的创建
一个进程的创建可以发生在以下几种情况下:
- 系统启动: 当计算机系统启动时,会自动创建一个或多个进程作为系统的初始进程。这些初始进程通常是操作系统内核的一部分,负责初始化系统资源、加载驱动程序和启动其他进程。
- 程序执行: 当执行一个可执行程序时,操作系统会创建一个新的进程来运行该程序。这个新创建的进程称为子进程,而执行程序的进程称为父进程。子进程是父进程的副本,它会继承父进程的代码、数据和资源,并开始执行程序的指令。
- 调用fork()函数: 通过调用系统调用函数
fork(),一个进程可以创建一个与自身相同的副本,即父进程和子进程。调用fork()函数后,当前进程会复制自身,创建一个全新的进程作为子进程,而原始进程则继续执行。父进程和子进程在调用fork()之后同时执行,但是它们可以根据fork()的返回值来区分自己的角色。 - 调用exec()函数: 通过调用系统调用函数
exec(),一个进程可以加载并执行一个新的可执行程序。exec()函数会替换当前进程的代码和数据,并开始执行新程序的指令。使用exec()函数创建的进程不是通过复制父进程而创建的,而是直接加载新的程序。
需要注意的是,进程的创建并不是立即发生的,而是在操作系统调度时才会真正创建和执行。操作系统根据调度策略和优先级来决定进程的创建和运行顺序。
补充汇编知识
1 | xchg rax rsp:交换rax和rsp的值 |
补充某些保护
CONFIG_MEMCG_KMEM:使得GFP_KERNEL与GFP_KERNEL_ACCOUNT会从不一样的kmalloc-xx中进行分配CONFIG_RANDOMIZE_KSTACK_OFFSET:这使得固定函数调用到内核栈底的偏移值是变化的SLAB_FREELIST_HARDENED:这使得 freelist 有保护,不能随意控制HARDENED_FREELIST:该机制通过以下方式提高自由链表的安全性:- 随机化指针:
HARDENED_FREELIST会对自由链表中的指针进行随机化处理,使攻击者难以预测或修改指针的值。这样可以防止攻击者利用已知的指针偏移或地址来修改自由链表的指针。 - 校验和保护:
HARDENED_FREELIST会使用校验和来验证自由链表中的指针是否被篡改。通过计算和验证校验和,可以检测指针是否被修改,从而防止攻击者对自由链表进行恶意修改。 - 隔离和分割:
HARDENED_FREELIST会将自由链表与其他内存区域进行隔离和分割,以减少攻击者对自由链表的访问和修改机会。这种隔离和分割可以通过物理或虚拟内存布局来实现。
- 随机化指针:
RANDOMIZE_FREELIST:可以提供以下安全性优势:- 防止指针猜测:攻击者通常会尝试猜测或推断自由链表中的指针值,以便修改它们以控制内存分配。通过随机化指针,攻击者无法准确猜测指针的值,从而增加攻击的困难度。
- 减少重复利用:某些堆漏洞(如双重释放)可能导致攻击者重复利用自由链表中的已释放内存块。通过随机化自由链表指针,可以降低攻击者成功利用重复利用漏洞的概率。
补充某些内核的知识
GFP_KERNEL
GFP_KERNEL 是 Linux 内核中用于内存分配的标志之一,它表示在内核中申请内存时使用的标志。
GFP 代表 “Get Free Page”,它是内核中用于分配页面(Page)的函数 __alloc_pages() 和 kmalloc() 的标志参数之一。GFP_KERNEL 是其中最常用的标志之一,它表示常规的内核内存分配。
使用 GFP_KERNEL 标志进行内存分配意味着:
- 内存分配是针对内核使用的,而不是用户空间。
- 内存分配是在常规内核上下文中进行的,例如进程上下文或中断上下文。
- 内存分配是可睡眠的,即如果没有足够的可用内存,调用者可能会被置于睡眠状态,直到有足够的内存可用。
GFP_KERNEL 标志通常用于在内核中进行常规的内存分配,例如数据结构的动态分配、缓存的分配等。它提供了一种默认的内存分配策略,适用于大多数内核代码的需求。
__GFP_HARDWALL
__GFP_HARDWALL 是 Linux 内核中的一个内存分配标志,用于在内核中进行内存分配时设置特定的行为。
__GFP_HARDWALL 标志的作用是在内存分配过程中强制执行硬壁(hardwall)策略。硬壁策略是一种内存分配的安全机制,用于防止内存资源的过度消耗。
当使用 __GFP_HARDWALL 标志进行内存分配时,内核会采取以下行为:
- 限制内存分配的数量:内核会限制每个进程或上下文中的内存分配数量,以防止资源过度消耗。
- 强制等待:如果没有足够的可用内存,内核会强制等待,直到有足够的内存可用,而不是尝试其他的内存回收或压缩策略。
通过使用 __GFP_HARDWALL 标志,内核可以确保内存分配不会无限制地消耗系统资源,从而提高系统的可靠性和稳定性。这对于关键任务和资源受限环境下的系统特别重要。
__GFP_NOWARN
__GFP_NOWARN 是 Linux 内核中的一个内存分配标志,用于在内核中进行内存分配时设置特定的行为。
__GFP_NOWARN 标志的作用是禁止内核在内存分配失败时发出警告或打印错误消息。通常,当内存分配失败时,内核会发出警告或打印错误消息,以提醒开发人员或系统管理员可能存在的问题。
使用 __GFP_NOWARN 标志进行内存分配时,内核会执行以下行为:
- 禁止警告信息:内核不会发出警告或打印错误消息,即使内存分配失败。
- 返回 NULL 或错误码:内核可能会返回 NULL 指针或特定的错误码,以表示内存分配失败,而不是发出警告消息。
一些指令
1 | ropper --file ./vmlinux --nocolor > g1 |
1 | //将 exp 进程绑定至指定核心的模板: |
提取vmlinux的脚本
1 |
|
管道
linux管道pipe详解_linux pipe-CSDN博客
管道的概念:
管道是一种最基本的IPC机制,作用于有血缘关系的进程之间,完成数据传递。调用pipe系统函数即可创建一个管道。有如下特质:
- 其本质是一个伪文件(实为内核缓冲区)
- 由两个文件描述符引用,一个表示读端,一个表示写端。
- 规定数据从管道的写端流入管道,从读端流出。
管道的原理: 管道实为内核使用环形队列机制,借助内核缓冲区(4k)实现。
管道的局限性:
① 数据自己读不能自己写。
② 数据一旦被读走,便不在管道中存在,不可反复读取。
③ 由于管道采用半双工通信方式。因此,数据只能在一个方向上流动。
④ 只能在有公共祖先的进程间使用管道。
常见的通信方式有,单工通信、半双工通信、全双工通信。
pipe函数
创建管道
int pipe(int pipefd[2]); 成功:0;失败:-1,设置errno
函数调用成功返回r/w两个文件描述符。无需open,但需手动close。规定:fd[0] → r; fd[1] → w,就像0对应标准输入,1对应标准输出一样。向管道文件读写数据其实是在读写内核缓冲区。
管道创建成功以后,创建该管道的进程(父进程)同时掌握着管道的读端和写端。如何实现父子进程间通信呢?通常可以采用如下步骤:
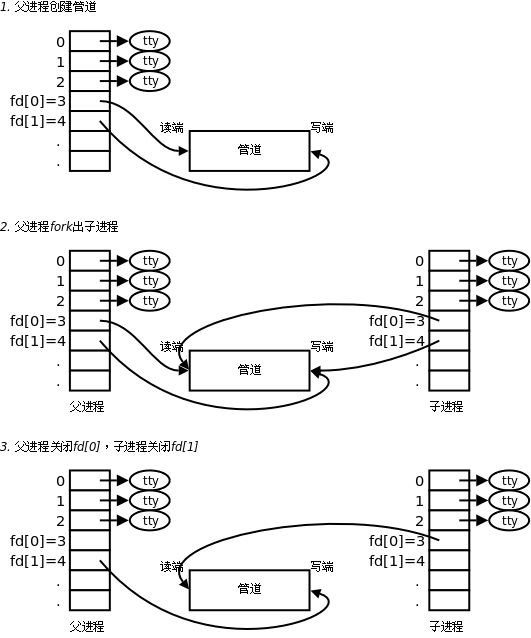
- 父进程调用pipe函数创建管道,得到两个文件描述符fd[0]、fd[1]指向管道的读端和写端。
- 父进程调用fork创建子进程,那么子进程也有两个文件描述符指向同一管道。
- 父进程关闭管道读端,子进程关闭管道写端。父进程可以向管道中写入数据,子进程将管道中的数据读出。由于管道是利用环形队列实现的,数据从写端流入管道,从读端流出,这样就实现了进程间通信。
seq_operation结构体
本文档的Copyleft归yfydz所有,使用GPL发布,可以自由拷贝,转载,转载时请保持文档的完整性,严禁用于任何商业用途。
msn: yfydz_no1@hotmail.com
来源:http://yfydz.cublog.cn
前言
在fs/seq_file.c中定义了关于seq操作的一系列顺序读取的函数,这些函数最早是在2001年就引入了,但以前内核中一直用得不多,而到了2.6内核后,许多/proc的只读文件中大量使用了seq函数处理。
以下内核源码版本为2.6.17.11。
2.seq相关数据结构
2.1 seq文件结构
1 | struct seq_file { |
struct seq_file描述了seq处理的缓冲区及处理方法,buf是动态分配的,大小不小于PAGE_SIZE,通常这个结构是通过struct file结构中的private_data来指向的。
1 | char *buf:seq流的缓冲区 |
2.2 seq操作结构
seq的操作结构比较简单,就是4个操作函数,完成开始、停止、显示和取下一个操作:
1 | /* include/linux/seq_file.h */ |
3.seq操作函数
seq操作包括以下一系列函数:
1 | int seq_open(struct file *, struct seq_operations *); |
打开seq流,为struct file分配struct seq_file结构,并定义seq_file的操作;
1 | ssize_t seq_read(struct file *, char __user *, size_t, loff_t *); |
从seq流中读数据到用户空间,其中循环调用了struct seq_file中的各个函数来读数据;
1 | ssize_t seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos) |
1 | loff_t seq_lseek(struct file *, loff_t, int); |
定位seq流当前指针偏移;
1 | int seq_release(struct inode *, struct file *); |
释放seq流所分配的动态内存空间,即struct seq_file的buf及其本身;
1 | int seq_escape(struct seq_file *, const char *, const char *); |
将seq流中需要进行转义的字符转换为8进制数字;
1 | int seq_putc(struct seq_file *m, char c); |
向seq流中写一个字符
1 | int seq_puts(struct seq_file *m, const char *s); |
向seq流中写一个字符串
1 | int seq_printf(struct seq_file *, const char *, ...) |
向seq流方式写格式化信息;
1 | int seq_path(struct seq_file *, struct vfsmount *, struct dentry *, char *); |
在seq流中添加路径信息,路径字符都转换为8进制数。
1 | int seq_release_private(struct inode *, struct file *); |
释放seq_file的private然后进行seq_release
3.用seq流填写/proc文件
以下使用文件/proc/net/ip_conntrack的生成代码来说明seq流的使用:
3.1 创立文件
以前2.4版本中使用proc_net_create()来建立/proc/net下的文件,现在使用seq流时要使用proc_net_fops_create()函数来创建,区别在于函数的最后一个参数,proc_net_create()的是一个函数指针,而proc_net_fops_create()的是一个文件操作指针:
1 | proc = proc_net_fops_create("ip_conntrack", 0440, &ct_file_ops); |
proc_net_fops_create()函数其实也很简单,调用create_proc_entry()函数建立/proc文件项,然后将文件项的操作结构指针指向所提供的文件操作指针:
1 | static inline struct proc_dir_entry *proc_net_fops_create(const char *name, |
3.2 文件操作结构
/proc/net/ip_conntrack所用的文件结构如下:
1 | static struct file_operations ct_file_ops = { |
可见,结构中除了open()函数是需要自定义外,其他的读、定位、释放函数都可以用seq标准函数。
3.3 open函数定义
open函数主要就是调用seq_open()函数将一个struct seq_operations结构和struct file链接起来,如果需要有私有数据的话,需要分配出动态空间作为struct seq_file的私有数据:
1 | static int ct_open(struct inode *inode, struct file *file) |
简单的如exp_open()函数,就只调用seq_open()函数就完了:
1 | static int exp_open(struct inode *inode, struct file *file) |
3.4 seq操作结构
1 | static struct seq_operations ct_seq_ops = { |
这个结构就是填写4个操作函数:
start()函数完成读数据前的一些预先操作,通常如加锁,定位数据记录位置等,该函数返回值就是show()函数第二个参数:
1 | static void *ct_seq_start(struct seq_file *seq, loff_t *pos) |
stop()函数完成读数据后的一些恢复操作,如解锁等:
1 | static void ct_seq_stop(struct seq_file *s, void *v) |
next()函数定位数据下一项:
1 | static void *ct_seq_next(struct seq_file *s, void *v, loff_t *pos) |
show()函数实现读数据过程,将要输出的数据直接用seq_printf()函数打印到seq流缓冲区中,由seq_printf()函数输出到用户空间:
1 | static int ct_seq_show(struct seq_file *s, void *v) |
结论
seq流函数的使用保证了数据能顺序输出,这也就是/proc只读文件中使用它的最大原因吧。
@###阅读情况:粗略了解
modprobe_path覆写
modprobe_path介绍
modprobe_path是用于在Linux内核中添加可加载的内核模块,当我们在Linux内核中安装或卸载新模块时,就会执行这个程序。他的路径是一个内核全局变量,默认为 /sbin/modprobe,可以通过如下命令来查看该值:
1 | cat /proc/sys/kernel/modprobe |
此外,modprobe_path存储在内核本身的modprobe_path符号中,且具有可写权限。也即普通权限即可修改该值。
而当内核运行一个错误格式的文件(或未知文件类型的文件)的时候,也会调用这个 modprobe_path所指向的程序。如果我们将这个字符串指向我们自己的sh文件 ,并使用 system或 execve 去执行一个未知文件类型的错误文件,那么在发生错误的时候就可以执行我们自己的二进制文件了。其调用流程如下:
1 | (1)do_execve() |
那么查看 __request_module 源码如下,本质就是调用了 call_usermodehelper函数:
1 | int __request_module(bool wait, const char *fmt, ...) |
接着查看 call_usermodehelper函数源码,该函数用于在内核空间中执行用户空间的程序,并且该程序具有root权限。这也保证了我们自己所写的 sh文件在被执行时,能执行具有root权限的功能,实现提权。
1 | call_usermodehelper(char *path, char **argv, char **envp, enum umh_wait wait); |
代码如下所示:
1 | system("echo -ne '#!/bin/sh\n/bin/cp /flag /tmp/flag\n/bin/chmod 777 /tmp/flag' > /tmp/getflag.sh"); |
- 首先创建了一个我们自己的 sh文件 geflag.sh,用于 将 /flag拷贝到 /tmp/flag下,并赋予 /tmp/flag为可读可写可执行权限。然后赋予 /tmp/getflag.sh可执行权限。
- 随后创建了一个错误格式头的文件 /tmp/fl,并赋予其可执行权限
- 当我们覆写了 modprobe_path为 /tmp/getflag.sh后,调用 system(“/tmp/fl”)触发错误,随后就能以root权限执行 /tmp/getflag.sh,完成将原本只能 root可读的flag拷贝到 /tmp目录下,并赋予可读权限
此外,我们该如何确定 modprobe_path符号的存储地址呢?在内核题目中,通常使用 cat /proc/kallsyms来获取符号地址,但是 modprobe_path并不在其中。这里我们可以考虑查找引用了modprobe_path符号的地址,来获取其地址。而在上面 __request_module代码中,即引用了 modprobe_path的地址。所以我们可以通过以下方法找到 modprobe_path地址:
- 先通过 /proc/kallsyms找到 __request_module地址
- 随后查看 __reques_module函数汇编,找到 modprobe_path的引用
1 | / # cat /proc/kallsyms | grep __request |
那么,总结一下该 技术的使用条件:
- 知道 modprobe_path地址
- 拥有一个任意地址写漏洞,用于修改 modprobe_path内容
@###阅读情况:大致了解
内核调试命令
查看保护
1 | cat /proc/cpuinfo # 查看所开保护 |
获取 ROP 地址
这块有时 ROPgadget 快,有时 ropper 快,随缘吧
ROPgadget
使用方法:
1 | ROPgadget --binary ./vmlinux > _gadget.txt |
ropper
使用方法:
1 | ropper --no-color -f ./vmlinux > gadget.txt |
获取函数地址
1 | lsmod # 查看装载驱动,也是获得内核文件加载的基地址 |
此处若是开了地址随机化,需要先改启动脚本,使 kaslr 变成 nokaslr,然后获取一个栈地址,将其记录
之后再把 nokaslr 改回 kaslr,运行脚本获得之前所记录地址处对应的新地址,做差,记录这个差值为 stackbase
之后把获得的所有的内核地址都加上这个 stackbase,即差值,才能获得在开启 kaslr 下的真实地址
gdb-multiarch 调试命令
一般来说用 gdb 就可以,跨平台的话就要用 gdb-multiarch
设置架构
在 startvm.sh 脚本上设置好端口后就可以用 gdb-multiarch 来调试了
首先要根据使用的 qemu 来设置系统架构,设置命令为set architecture 内核系统架构
架构有很多,我用的是 qemu 3.0.0,是在 Ubuntu 16.04 下自行编译安装的,因为默认版本很老
不过 Ubuntu 18.04 之后的 qemu 都是 3.0.0 以后的版本,所以按需搭配自己喜欢的环境就好
架构一览:
1 | aarch64 mips:4400 |
假使 startvm.sh 上面所写的 qemu 种类是 qemu-system-x86_64
那么就用 i386:x86-64 架构,输入命令如下:
1 | set architecture i386:x86-64 |
连接端口
命令如下:
1 | target remote localhost:1234 |
读取内核文件符号表及内核加载基地址
先用 extract-vmlinux 命令提取 vmlinux 文件,命令如下:
1 | extract-vmlinux bzImage > vmlinux |
然后先用 root 用户登录,在里面输入 lsmod 获得模块加载的基地址:
1 | /home/pwn # $ lsmod |
之后启动的时候这么启动:
1 | gdb-multiarch ./vmlinux -ex "set architecture i386:x86-64" -ex "add-symbol-file ./baby.ko 0xffffffffc0000000" -ex "target remote localhost:2222" |
eth0/1
eth0 eth0:1 和eth0.1三者的关系对应于物理网卡、子网卡、虚拟VLAN网卡的关系:
物理网卡:物理网卡这里指的是服务器上实际的网络接口设备,这里我服务器上双网卡,在系统中看到的2个物理网卡分别对应是eth0和eth1这两个网络接口。
子网卡:子网卡在这里并不是实际上的网络接口设备,但是可以作为网络接口在系统中出现,如eth0:1、eth1:2这种网络接口。它们必须要依赖于物理网卡,虽然可以与物理网卡的网络接口同时在系统中存在并使用不同的IP地址,而且也拥有它们自己的网络接口配置文件。但是当所依赖的物理网卡不启用时(Down状态)这些子网卡也将一同不能工作。
虚拟VLAN网卡:这些虚拟VLAN网卡也不是实际上的网络接口设备,也可以作为网络接口在系统中出现,但是与子网卡不同的是,他们没有自己的配置文件。他们只是通过将物理网加入不同的VLAN而生成的VLAN虚拟网卡。如果将一个物理网卡通过vconfig命令添加到多个VLAN当中去的话,就会有多个VLAN虚拟网卡出现,他们的信息以及相关的VLAN信息都是保存在/proc/net/vlan/config这个临时文件中的,而没有独自的配置文件。它们的网络接口名是eth0.1、eth1.2这种名字。
注意:当需要启用VLAN虚拟网卡工作的时候,关联的物理网卡网络接口上必须没有IP地址的配置信息,并且,这些主物理网卡的子网卡也必须不能被启用和必须不能有IP地址配置信息。这个在网上看到的结论根据我的实际测试结果来看是不准确的,物理网卡本身可以绑定IP,并且给本征vlan提供通信网关的功能,但必须是在802.1q下。
socket
socket就是插座 ( 中文翻译成套接字有点莫名其妙),运行在计算机中的两个程序通过socket建立起一个通道,数据在通道中传输。 socket把复杂的TCP/IP协议族隐藏了起来,对程序员来说只要用好socket相关的函数,就可以完成网络通信。
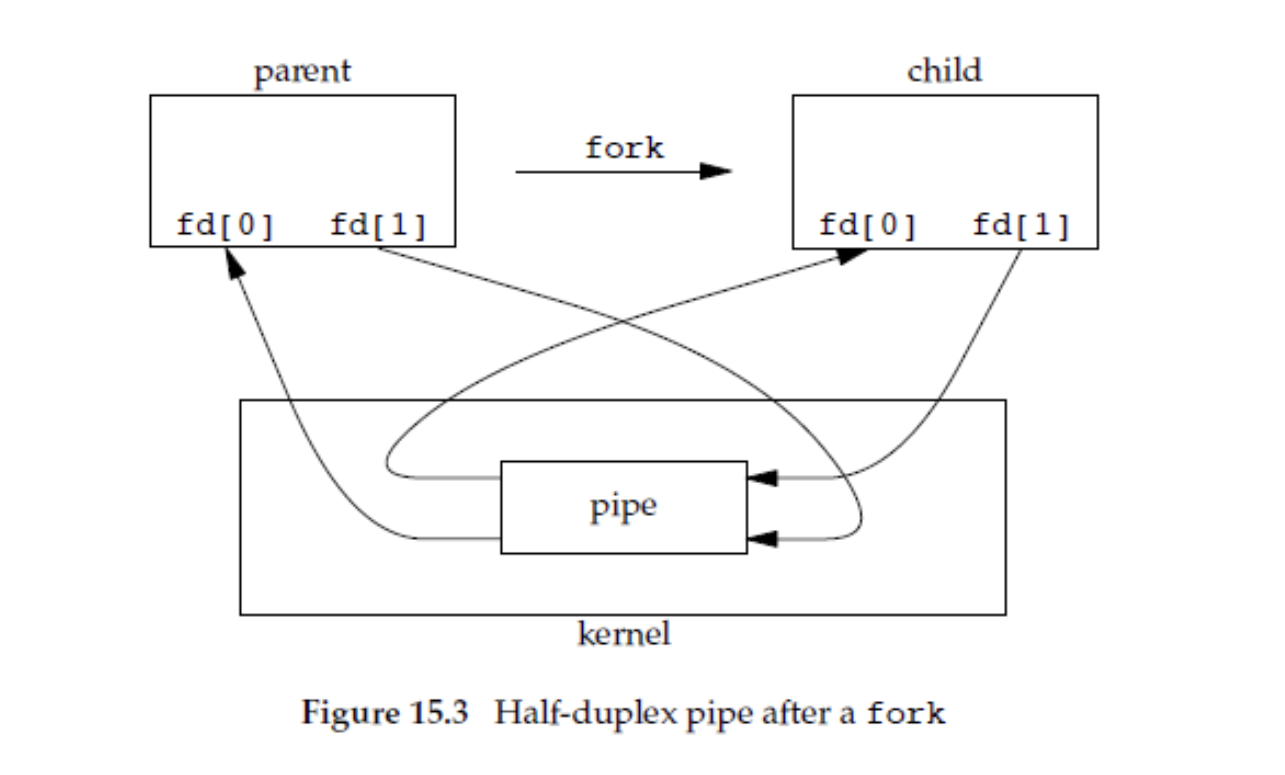
管道
管道的实质上就是一个文件系统,然后pipe指令会返回两个文件描述符,一个读一个写,而管道是单向的,就是在输入的时候不能输出,因此通常创建pipe两个管道一个用于输出,一个用于输入,管道分为管道本身(就是一个普通的类似流之类的),和管道数据(处于一个空间)。
在创建子进程的时候,管道本身会被复制,到那时管道数据确实共享的,这样就能实现数据的传输
远程脚本
pack.sh
1 |
|
gdbinit
1 | file ./vmlinux |
远程脚本
为了减小远程exp的体积,使用musl进行静态编译()
1 | import sys |