/* Flags (formerly in max_fast). */ /* 标志位(以前在 max_fast 中) */ int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */ /* Note this is a bool but not all targets support atomics on booleans. */ /* 如果 fastbin 块包含最近插入的空闲块,则设置为 1 */ /* 注意,这是一个布尔值,但并非所有目标平台都支持对布尔值的原子操作 */ int have_fastchunks;
/* Fastbins */ mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */ /* 最顶层块的基址 -- 不在任何 bin 中 */ mchunkptr top;
/* The remainder from the most recent split of a small request */ /* 最近一次拆分小型请求产生的剩余块 */ mchunkptr last_remainder;
/* Normal bins packed as described above */ /* 正常 bins,按照上述描述进行打包 */ mchunkptr bins[NBINS * 2 - 2];
/* Linked list */ /* 链表 */ structmalloc_state *next;
/* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */ /* 用于空闲 arenas 的链表。访问该字段由 arena.c 中的 free_list_lock 进行序列化 */ structmalloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */ /* 附加到该 arena 的线程数。如果该 arena 在空闲列表中,则为 0。访问该字段由 arena.c 中的 free_list_lock 进行序列化 */ INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */ /* 在该 arena 中从系统分配的内存 */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
victim = _int_malloc (ar_ptr, bytes); /* Retry with another arena only if we were able to find a usable arena before. */ if (!victim && ar_ptr != NULL) { LIBC_PROBE (memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry (ar_ptr, bytes); victim = _int_malloc (ar_ptr, bytes); }
if (ar_ptr != NULL) (void) mutex_unlock (&ar_ptr->mutex);
/* arena_get() acquires an arena and locks the corresponding mutex. First, try the one last locked successfully by this thread. (This is the common case and handled with a macro for speed.) Then, loop once over the circularly linked list of arenas. If no arena is readily available, create a new one. In this latter case, `size' is just a hint as to how much memory will be required immediately in the new arena. */
#define arena_get(ptr, size) do { \ ptr = thread_arena; \ arena_lock (ptr, size); \ } while (0)
#define arena_lock(ptr, size) do { \ if (ptr && !arena_is_corrupt (ptr)) \ (void) mutex_lock (&ptr->mutex); \ else \ ptr = arena_get2 ((size), NULL); \ } while (0)
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from mmap. */ if (__glibc_unlikely (av == NULL)) { void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; }
/* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */
if (chunk_is_mmapped (p)) return; /* mmapped chunks have no next/prev *///如果是mmap的heap直接退出检查
/* Check whether it claims to be in use ... */ assert (inuse (p)); //通过p的地址+size来指向下一个chunk判断本chunk是否正在使用,如果为空闲则退出//fastbin的特性,释放但不置0
next = next_chunk (p);
/* ... and is surrounded by OK chunks. Since more things can be checked with free chunks than inuse ones, if an inuse chunk borders them and debug is on, it's worth doing them. */ if (!prev_inuse (p)) { /* Note that we cannot even look at prev unless it is not inuse */ mchunkptr prv = prev_chunk (p); assert (next_chunk (prv) == p); //如果前一个chunk为空闲块则检查其next_chunk是不是本chunk do_check_free_chunk (av, prv); //调用在下方 }
staticvoid do_check_malloced_chunk(mstate av, mchunkptr p, INTERNAL_SIZE_T s) { /* same as recycled case ... */ do_check_remalloced_chunk (av, p, s);
/* ... plus, must obey implementation invariant that prev_inuse is always true of any allocated chunk; i.e., that each allocated chunk borders either a previously allocated and still in-use chunk, or the base of its memory arena. This is ensured by making all allocations from the `lowest' part of any found chunk. This does not necessarily hold however for chunks recycled via fastbins. */ /* ... 另外,必须遵守实现不变式,即任何分配的内存块的prev_inuse始终为真; 换句话说,每个分配的内存块要么与先前分配且仍在使用的内存块相邻, 要么与其内存区域的基址相邻。通过从任何找到的内存块的“最低”部分进行所有分配, 可以确保这一点。然而,通过快速链表回收的内存块不一定满足这个条件。 */
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */
/* maintain large bins in sorted order */ if (fwd != bck) //largebin本身有chunk { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert ((bck->bk->size & NON_MAIN_ARENA) == 0); if ((unsignedlong) (size) < (unsignedlong) (bck->bk->size)) //小于最小的size { fwd = bck; bck = bck->bk;
if (!in_smallbin_range (nb)) { bin = bin_at (av, idx);
/* skip scan if empty or largest chunk is too small */ if ((victim = first (bin)) != bin && //victim初始是本bin最大的chunk (unsignedlong) (victim->size) >= (unsignedlong) (nb)) //largebin非空且要分配的size小于largebin最大的size { victim = victim->bk_nextsize; while (((unsignedlong) (size = chunksize (victim)) < //找到size恰好大于等于要分配size的chunk (unsignedlong) (nb))) victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last (bin) && victim->size == victim->fd->size) victim = victim->fd; //尽量不取带有nextsize的chunk
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected. The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */
for (;; ) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) //该map没有相应的chunk { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ((map = av->binmap[block]) == 0); //如果能不满足说明该map对应的block肯定有满足条件的chunk
bin = bin_at (av, (block << BINMAPSHIFT)); bit = 1; }
/* Advance to bin with set bit. There must be one. */ /* 前进到具有设置位的存储桶。必须存在一个存储桶。 */ while ((bit & map) == 0) //找到对应的bin { bin = next_bin (bin); bit <<= 1; assert (bit != 0); //bit!=0 }
/* Inspect the bin. It is likely to be non-empty */ victim = last (bin);
/* If a false alarm (empty bin), clear the bit. */ /* 如果是误报(空的存储桶),则清除该位。 */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin (bin); bit <<= 1; }
else//接下来就是常规分割了 { size = chunksize (victim);
/* We know the first chunk in this bin is big enough to use. */ assert ((unsignedlong) (size) >= (unsignedlong) (nb));
remainder_size = size - nb;
/* unlink */ unlink (av, victim, bck, fwd);
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset (victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; }
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks (av)) { malloc_consolidate (av); /* restore original bin index */ if (in_smallbin_range (nb)) idx = smallbin_index (nb); else idx = largebin_index (nb); }
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */ mchunkptr old = *fb, old2; //old=*fb,定义old2 unsignedint old_idx = ~0u; do { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ if (__builtin_expect (old == p, 0)) //检查链表头是不是要释放的chunk,避免double free { errstr = "double free or corruption (fasttop)"; goto errout; } /* Check that size of fastbin chunk at the top is the same as size of the chunk that we are adding. We can dereference OLD only if we have the lock, otherwise it might have already been deallocated. See use of OLD_IDX below for the actual check. */ /* 检查顶部的 fastbin 块的大小是否与我们要添加的块的大小相同。 只有在持有锁的情况下才能引用 OLD,否则它可能已经被释放。 下面的 OLD_IDX 的使用是实际检查的部分。 */ if (have_lock && old != NULL) old_idx = fastbin_index(chunksize(old)); p->fd = old2 = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2)) != old2); //总的来说目的就是将p插入到fastbin里
/* Lightweight tests: check whether the block is already the top block. */ if (__glibc_unlikely (p == av->top)) //p不能是top chunk { errstr = "double free or corruption (top)"; goto errout; } /* Or whether the next chunk is beyond the boundaries of the arena. */ if (__builtin_expect (contiguous (av) && (char *) nextchunk >= ((char *) av->top + chunksize(av->top)), 0)) //内存块连续且nextchunk超出边界 { errstr = "double free or corruption (out)"; goto errout; } /* Or whether the block is actually not marked used. */ if (__glibc_unlikely (!prev_inuse(nextchunk))) //nextchunk的p位要为1 { errstr = "double free or corruption (!prev)"; goto errout; }
if (nextchunk != av->top) { //如果nextchunk不是topchunk /* get and clear inuse bit */ nextinuse = inuse_bit_at_offset(nextchunk, nextsize); //设置nextchunk的p位
/* Place the chunk in unsorted chunk list. Chunks are not placed into regular bins until after they have been given one chance to be used in malloc. */
/* If freeing a large space, consolidate possibly-surrounding chunks. Then, if the total unused topmost memory exceeds trim threshold, ask malloc_trim to reduce top. Unless max_fast is 0, we don't know if there are fastbins bordering top, so we cannot tell for sure whether threshold has been reached unless fastbins are consolidated. But we don't want to consolidate on each free. As a compromise, consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */
if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { //如果该chunk不在fastbin范围里 if (have_fastchunks(av)) malloc_consolidate(av); //整理fastbin
if (av == &main_arena) { #ifndef MORECORE_CANNOT_TRIM if ((unsignedlong)(chunksize(av->top)) >= (unsignedlong)(mp_.trim_threshold)) systrim(mp_.top_pad, av); //收缩堆 #endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av));
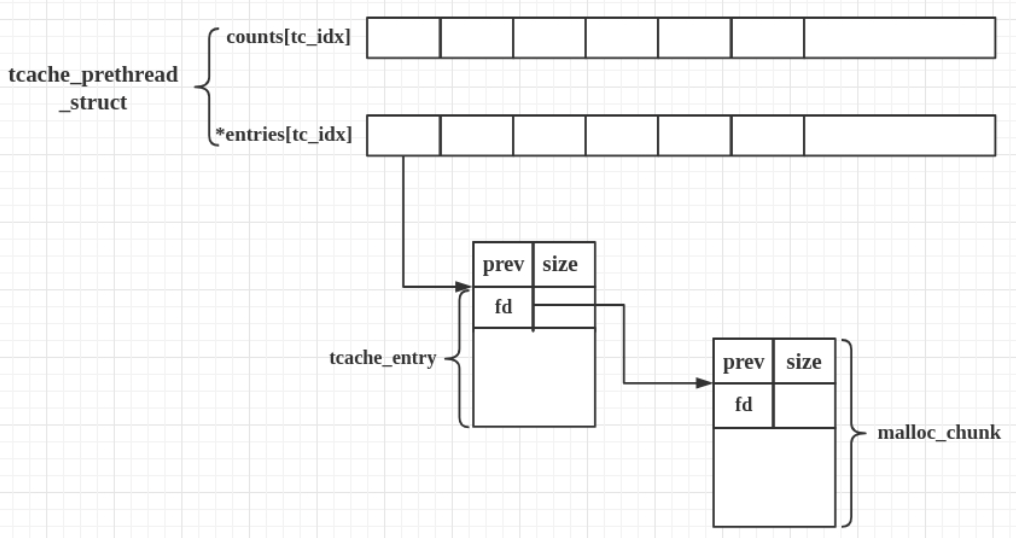
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ typedefstructtcache_entry { structtcache_entry *next; } tcache_entry;
/* There is one of these for each thread, which contains the per-thread cache (hence "tcache_perthread_struct"). Keeping overall size low is mildly important. Note that COUNTS and ENTRIES are redundant (we could have just counted the linked list each time), this is for performance reasons. */ typedefstructtcache_perthread_struct { char counts[TCACHE_MAX_BINS]; tcache_entry *entries[TCACHE_MAX_BINS]; } tcache_perthread_struct;
#if USE_TCACHE /* int_free also calls request2size, be careful to not pad twice. */ size_t tbytes; checked_request2size (bytes, tbytes); size_t tc_idx = csize2tidx (tbytes);
if (victim != NULL) { if (SINGLE_THREAD_P) *fb = victim->fd; else REMOVE_FB (fb, pp, victim); if (__glibc_likely (victim != NULL)) { size_t victim_idx = fastbin_index (chunksize (victim)); if (__builtin_expect (victim_idx != idx, 0)) malloc_printerr ("malloc(): memory corruption (fast)"); check_remalloced_chunk (av, victim, nb); #if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = *fb) != NULL) { if (SINGLE_THREAD_P) *fb = tc_victim->fd; else { REMOVE_FB (fb, pp, tc_victim); if (__glibc_unlikely (tc_victim == NULL)) break; } tcache_put (tc_victim, tc_idx); } } #endif void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; } } }
#if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) //tcache存在,且tc_idx对应的tcache存在 { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */ while (tcache->counts[tc_idx] < mp_.tcache_count //no full && (tc_victim = last (bin)) != bin) //链表有多个节点 { if (tc_victim != 0) { bck = tc_victim->bk; set_inuse_bit_at_offset (tc_victim, nb); if (av != &main_arena) set_non_main_arena (tc_victim); bin->bk = bck; bck->fd = bin;
#if USE_TCACHE /* Fill cache first, return to user only if cache fills. We may return one of these chunks later. */ if (tcache_nb && tcache->counts[tc_idx] < mp_.tcache_count) //如果unsortedbin的符合tcache条件 { tcache_put (victim, tc_idx); //放到tcache里 return_cached = 1; continue; } else { #endif
如果unsortedbin找到的符合tcache,那么先放到tcache里
1 2 3 4 5 6 7 8 9 10 11
#if USE_TCACHE /* If we've processed as many chunks as we're allowed while filling the cache, return one of the cached ones. */ ++tcache_unsorted_count; if (return_cached && mp_.tcache_unsorted_limit > 0 && tcache_unsorted_count > mp_.tcache_unsorted_limit) { return tcache_get (tc_idx); } #endif
if (__glibc_unlikely (e->key == tcache)) { tcache_entry *tmp; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = tmp->next) if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ }
if (SINGLE_THREAD_P) *fb = REVEAL_PTR (tc_victim->fd);
1
*fb = REVEAL_PTR (tc_victim->fd);
fastbin和tcache的时候,会对加密后的指针解密
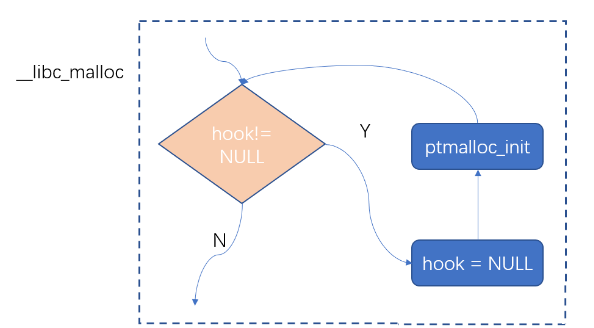
__libc_free
没变化
__int_free
1
p->fd = PROTECT_PTR (&p->fd, old);
fastbin的时候对指针加密,同时判断tcache double free的时候会解密
tcache&&fastbin加密
1 2 3 4 5 6 7 8 9 10 11 12
/* Safe-Linking: Use randomness from ASLR (mmap_base) to protect single-linked lists of Fast-Bins and TCache. That is, mask the "next" pointers of the lists' chunks, and also perform allocation alignment checks on them. This mechanism reduces the risk of pointer hijacking, as was done with Safe-Unlinking in the double-linked lists of Small-Bins. It assumes a minimum page size of 4096 bytes (12 bits). Systems with larger pages provide less entropy, although the pointer mangling still works. */ #define PROTECT_PTR(pos, ptr) \ ((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr))) #define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
/* Process-wide key to try and catch a double-free in the same thread. */ staticuintptr_t tcache_key;
/* The value of tcache_key does not really have to be a cryptographically secure random number. It only needs to be arbitrary enough so that it does not collide with values present in applications. If a collision does happen consistently enough, it could cause a degradation in performance since the entire list is checked to check if the block indeed has been freed the second time. The odds of this happening are exceedingly low though, about 1 in 2^wordsize. There is probably a higher chance of the performance degradation being due to a double free where the first free happened in a different thread; that's a case this check does not cover. */ staticvoid tcache_key_initialize(void) { if (__getrandom (&tcache_key, sizeof(tcache_key), GRND_NONBLOCK) != sizeof (tcache_key)) { tcache_key = random_bits (); #if __WORDSIZE == 64 tcache_key = (tcache_key << 32) | random_bits (); #endif } }